
13 min to read
Automation with AWS Lambda Functions
Automate a Website Backend with Serverless Functions

Automation with AWS Lambda Functions
Overview of Serverless Computing
What’s Serverless Computing?
“Serverless computing is a cloud computing model where the cloud provider dynamically manages the allocation and provisioning of servers. Developers focus on writing code without worrying about server management.”
Characteristics of serverless architecture:
- No server management: Cloud provider handles server provisioning and maintenance
- Pay-per-use pricing: Users are charged based on actual usage rather than provisioned capacity
- Auto-scaling: Resources scale automatically based on demand
Serverless architectures offer the following for modern application development:
- Agility
- Scalability
- Cost-effectiveness
Automation with Serverless
The following advangates:
1) Serverless Architecture: serverless functions operate on a serverless model, which means you don’t need to provision or manage servers. This significantly reduces the overhead associated with server maintenance, patching, and administration, allowing you to focus on writing code that serves your business logic.
2) Event-Driven: serverless functions are inherently event-driven, making them ideal for automation tasks. This capability enables you to automate responses to specific changes in your environment, such as processing files uploaded to S3, reacting to database changes, or handling web request events via API Gateway.
3) Scalability: serverless functions can automatically scale your application by running code in response to each trigger. Your code runs in parallel and processes each trigger individually, scaling precisely with the size of the workload, from a few requests per day to thousands per second. This makes it highly suitable for automation tasks that might experience variable loads.
4) Cost-Effectiveness: with serverless functions, you pay only for the compute time you consume. There is no charge when your code is not running. For automation tasks that are sporadic or only need to run in response to specific events, this can lead to significant cost savings compared to running dedicated infrastructure 24/7.
5) Rapid Development and Deployment: serverless functions allow for quick iterations and deployments since you can easily update your function code to add or modify automation tasks. This agility is beneficial for evolving automation needs and experimenting with new automation strategies without extensive infrastructure changes.
6) Customization and Control: serverless functions provide a high degree of customization, allowing you to write functions in various programming languages such as Python, Node.js, Java, and Go. This flexibility lets you tailor your automation logic to your specific requirements and leverage existing libraries and SDKs.
7) Security and Compliance: In the case of AWS Lambda: these serverless functions adhere to AWS’s high standards of security, ensuring that your automation tasks are executed in a secure environment. It integrates with AWS IAM (Identity and Access Management), allowing you to set fine-grained access controls on your Lambda functions. Additionally, AWS Lambda is compliant with many compliance programs, which can be a crucial consideration for automation tasks in regulated industries.
Different Cloud Providers for Serverless Automations:
 Top Providers: Amazon, Microsoft, and Google
Top Providers: Amazon, Microsoft, and Google
What is AWS Lambda?
Definition of AWS Lambda:
- AWS Lambda is a serverless compute service provided by Amazon Web Services (AWS) that lets you run code without provisioning or managing servers
- It automatically scales to handle incoming requests and charges only for the compute time consumed
Key features and Capabilities:
- Event-driven programming: Lambda functions can be triggered by events from various AWS services or custom sources
- Support for multiple programming languages: Lambda supports popular programming languages like Node.js, Python, Java, and more
- Integration with other AWS services: Lambda seamlessly integrates with other AWS services such as S3, DynamoDB, API Gateway, etc
Benefits of using AWS Lambda
- Cost-effective: Pay only for the compute time consumed by the function
- Scalable: Automatically scales to handle any workload
- Reduced operational overhead: Eliminates the need for server provisioning, maintenance, and scaling
Pricing The monthly request price is $0.20 per one million requests and the free tier provides 1 million request per month. This pay-on-demand model could be a cheaper solution than having a dedicated backend server running all the time
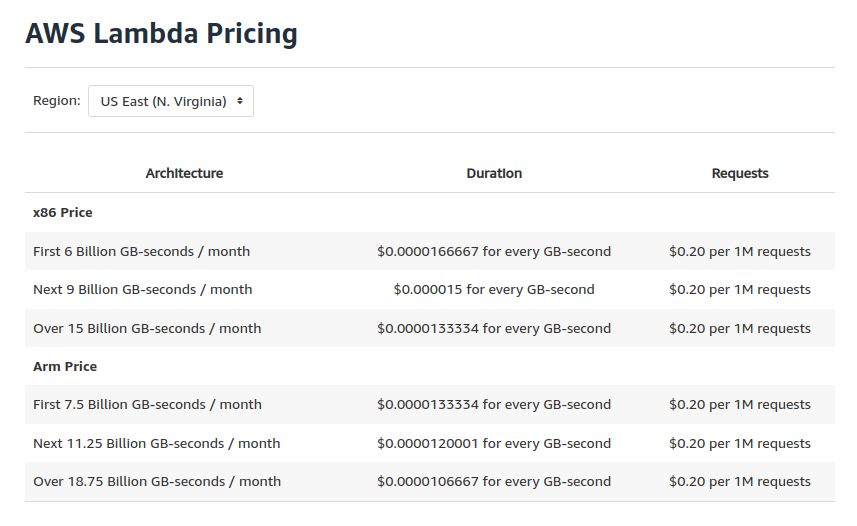 Lambda Pricing, prices taking from AWS site [1]
Lambda Pricing, prices taking from AWS site [1]
Use cases of AWS Lambda (Examples)
Example 1
- Real-time file processing: Process files uploaded to S3 buckets in real-time
Example 2:
- IoT data processing: Handle and analyze data from IoT devices
Example 3:
- Web application backends: Power serverless APIs and backend services for web applications
Example 4:
- Scheduled tasks and batch processing: Run scheduled tasks or batch jobs at specified intervals
Example 5:
- Chatbots and AI/ML applications: Implement chatbots or perform real-time data analysis using machine learning models
Example 6:
- Mobile and web application backends: Build scalable backends for mobile and web applications without managing servers
This article will focus on Example 3 and a future article will focus on Example 4.
How AWS Lambda Works
Lambda functions are triggered by events, and AWS automatically provisions and manages the infrastructure to execute the code. Each Lambda function consists of code, associated dependencies, and configuration.
API Gateway Trigger: For a function triggered by an API Gateway event, the event object would contain information about the HTTP request, such as the HTTP method, path, headers, query string parameters, and, if applicable, the request body.
{
"httpMethod": "POST",
"path": "/example/path",
"headers": {
"Content-Type": "application/json"
},
"queryStringParameters": {
"param1": "value1"
},
"body": "{\"key\":\"value\"}"
}
Limitations
Some notable limitations include:
- Execution Time Limit: Lambda functions have a maximum execution time limit, which, as of my last update, is set at 15 minutes.
- “Cold Starts”: Lambda functions can experience what’s known as “cold starts,” which is the latency experienced when invoking a Lambda function after it has been idle for some time. This can be a concern for applications requiring consistent, low-latency responses
- Resource Limits: AWS Lambda imposes limits on the amount of compute and memory resources available to each function. If your application requires more resources than Lambda can provide, it might not be the best fit
- Continuous Processing: Lambda is designed to respond to events and is not intended for continuous processing or long-running applications. Workloads that require continuous data processing might be better served by other compute services like EC2 or ECS
Demo
Consider the following architecture:
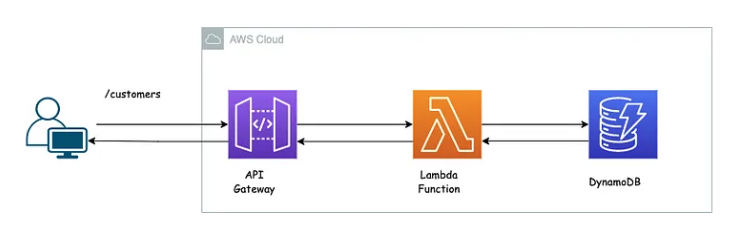 Simple web Architecture, example taken from [2]
Simple web Architecture, example taken from [2]
We want to demostrate a simple Flask application that connects to a DynamoDB via Lambda Functions and an API.
In this example, we want to demostrate two basic use cases:
- a GET request that gets a list of users from a
userstable in DynamoDB - a POST request that adds a new user to the
userstable in DynamoDB via a web form
In Flask, we have a GET users/ endpoint that looks like this:
API_GATEWAY = os.environ.get("API_GATEWAY_URL")
GET_USERS_ENDPOINT = "users"
@app.route("/users")
def get_users():
logger.info("Got GET request on `/users` endpoint")
endpoint_url = f"{API_GATEWAY}/{GET_USERS_ENDPOINT}"
try:
# Make GET request to API Gateway endpoint
response = requests.get(endpoint_url)
# Check if request was successful (status code 200)
if response.status_code == 200:
# Parse JSON response
users = response.json().get("body")
logger.info("Users retrieved from API Gateway:")
logger.info(users)
return users
else:
logger.error(
f"Failed to retrieve users. Status code: {response.status_code}"
)
except Exception as e:
logger.error(f"An error occurred: {str(e)}")
Here, we make a GET request to a variable endpoint_url which is a url pointing to our API Gateway. This url looks like this:
https://<API_GATEWAY_ID>.execute-api.<AWS_REGION>.amazonaws.com/<API_GATEWAY_ENDPOINT>
Since we are using us-east-1 as our primary region:
https://<API_GATEWAY_ID>.execute-api.us-east-1.amazonaws.com/users
The API Gateway has a GET endpoint named users which calls a lambda function api_get_users which itself gets the list of all users from a DynamoDB users table. The lambda api_get_users looks like this:
import json
import decimal
import boto3
class DecimalEncoder(json.JSONEncoder):
def default(self, o):
if isinstance(o, decimal.Decimal):
# Convert decimal instances to strings to preserve precision.
return str(o)
return super(DecimalEncoder, self).default(o)
def lambda_handler(event, context):
#print("Received event: " + json.dumps(event))
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('users')
# Scan the table (Note: Use query for more efficient, key-based access)
response = table.scan()
items = response['Items']
return {
'statusCode': 200,
'body': json.dumps(items, cls=DecimalEncoder)
}
On our browser, we have a list of users:
[
{
"user_id" : 0,
"firstname" : "Santiago",
"lastname" : "Potter",
"affiliation" : "automatemore",
"email" : "santiago@semanttica.com"
},
{
...
}
]
Now, we want to demostrate a POST Request. In Flask, we have two endpoints:
API_GATEWAY = os.environ.get("API_GATEWAY_URL")
ADD_USER_ENDPOINT = "add_user"
@app.route("/add_user")
def add_user():
logger.info("Got GET request on `add_user` endpoint")
return render_template("new_user.html")
@app.route("/add_new_user", methods=["POST"])
def add_new_user():
logger.info("Got POST request on `/add_new_user` endpoint")
form_data = request.form.to_dict()
endpoint_url = f"{API_GATEWAY}/{ADD_USER_ENDPOINT}"
response = requests.post(
endpoint_url,
json=form_data,
headers={"Content-Type": "application/json"},
)
# Check if the request was successful
if response.status_code == 200:
return jsonify({"message": "User created successfully"}), 200
else:
# Handle error responses
return (
jsonify({"message": "Failed to create user", "error": response.text}),
response.status_code,
)
When we go to our /add_user endpoint in our browser, we see a simple html form asking to input: firstname, lastname, email, and affiliation. When we submit the form, that generates a POST request to our /add_new_user endpoint which itself makes a POST request to API Gateway. Notice that our endpoint_url variable here is a little bit different than in our previous case as we have a different endpoint ADD_USER_ENDPOINT as part of the url.
https://<API_GATEWAY_ID>.execute-api.us-east-1.amazonaws.com/add_user
The API Gateway has a POST endpoint named add_users which calls a lambda function api_add_user which itself adds a new user to our DynamoDB users table. The lambda api_add_user looks like this:
import json
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('users')
def lambda_handler(event, context):
#print("Received event: " + json.dumps(event))
try:
body = event
except (KeyError, TypeError, json.JSONDecodeError):
return {'statusCode': 400, 'body': 'Invalid request'}
# Extract and validate data
user_id = body.get('user_id') # Assumes that user_id is entered in the webform in Flask
firstname = body.get('firstname')
lastname = body.get('lastname')
affiliation = body.get('affiliation')
email = body.get('email')
if not all([user_id, firstname, lastname, email]):
return {'statusCode': 400, 'body': json.dumps({'message': 'Missing required fields'})}
try:
response = table.put_item(
Item={
'user_id': int(user_id),
'firstname': firstname,
'lastname': lastname,
'affiliation': affiliation,
'email': email
}
)
print("Put Item Response:", response)
except Exception as e:
print("Error saving to DynamoDB:", str(e))
return {'statusCode': 500, 'body': json.dumps({'message': 'Error saving user'})}
return {'statusCode': 200, 'body': json.dumps({'message': 'User saved successfully', 'user_id': user_id})}
Finally, if we call our GET /users endpoint again, we should see a list with our new addition. This demo hides some details such as the deployment of the API on API Gateway, the permissions for the lambdas (one has read-only, and the other one has read-write), the CloudWatch logging, and other IAM permissions to make this all happen. These details are ommitted because we simply wanted to demostrate the use of Lambda functions and not focus on a full REST API demo.
References:
[1] Lambda Pricing
[2] Build a REST API with API Gateway, AWS Lambda, DynamoDB & AWS CDK


Comments